
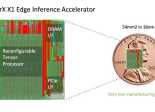
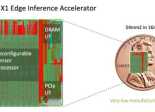
Le module Infer X1M du californien Flex Logix, fournisseur de FPGA embarqués sous forme d’IP (eFPGA) et de moteurs d'accélération neuronale, offre la possibilité d’utiliser de manière simple ses technologies grâce à une plate-forme de petites dimensions (22 x 80 mm) au format M.2, donc facilement insérable sur un connecteur PCIe. Le tout pour une enveloppe thermique de 6 W à 8,2 W.
La carte, lancée désormais en production de volume, intègre la puce InferX X1 de Flex Logix annoncée en 2020. Celle-ci est capable d’exécuter, selon la société, un algorithme de détection et de reconnaissance d’objets Yolov3 30% plus rapidement que le SoC Jetson Xavier de Nvidia. La version de la puce installée sur la carte serait même capable, selon Flex Logix, de faire tourner des modèles Yolov5.
Avec une empreinte silicium de 54 mm2 seulement (dans un procédé de fabrication 16 nm), la puce permet la mise en œuvre d’inférences pour des algorithmes d’intelligence artificielle de haute performance. Elle s’appuie sur la technologie brevetée d’interconnexion à double densité XFLX que l’Américain utilise dans ses eFPGA, associée à un TPU (Tensor Processing Unit) constitué de 64 processeurs Tensor unidimensionnels, étroitement couplés avec 8 Mo de mémoire SRam par des connexions reconfigurables à très haute vitesse (quelques millionièmes de seconde). Le eFPGA de son côté est doté de 4 Mo de mémoire RAM DDR3. L’ensemble étant capable de gérer de manière optimale les diverses opérations que nécessite l’exécution des réseaux de neurones.
Les cartes Infer X1M initialement annoncées en 2021 sont optimisées, d’après Flex Logix qui reste avare de détails techniques, pour l’analyse de grands modèles et le traitement images supérieures à 1 mégapixels, ce qui offrirait aux utilisateurs la possibilité de mettre en place des applications de détection d'objets hautes performances et à faible consommation d'énergie, notamment pour les systèmes robotiques et de vision industrielle.
Flex Logix fournit également une suite d'outils logiciels pour accompagner les cartes, avec notamment un environnement qui porte les modèles ONNX (Open Neural Network Exchange, écosystème d’algorithmes d’IA en open source disponible sur GitHub) pour qu'ils s'exécutent correctement sur la carte X1M, ainsi que des pilotes logiciels avec des API externes conçues pour que les applications puissent configurer et déployer des modèles, ainsi que des API internes pour gérer les fonctions de bas niveau conçues pour contrôler et surveiller la carte X1M.
Vous pouvez aussi suivre nos actualités sur la vitrine LinkedIN de L'Embarqué consacrée à l’intelligence artificielle dans l’embarqué : Embedded-IA



 300x300px.png)