
Annoncée lors du dernier salon CES qui s’est déroulé en janvier 2026 à Las Vegas (Etas-Unis) puis présentée dans une démonstration en réel lors de l’événement Embedded World 2026 qui s’est tenu à Nüremberg (Allemagne) en mars, la puce système CV7 de l’américain Ambarella, un concepteur de circuits intégrés de traitement vidéo et de vision artificielle, vise le marché des caméras grands publics.
Cette puissante puce-système de vision 8K, gravée en 4 nm, et intégrant des algorithmes d’intelligence embarquée (IA) apporte la notion de perception multisensorielle grâce à une combinaison de traitement de multi-flux video simultanés et d’IA embarqué avancé avec une très faible consommation d'énergie.
Les applications ciblées sont notamment les produits grand public 8K avancés fondés sur l'IA (caméras d'action et caméras 360°), les caméras de sécurité multi-capteurs pour entreprises, la robotique, les drones, l'automatisation industrielle et les dispositifs de visioconférence haute performance.
Selon Ambarella, le circuit CV7 est en outre adapté aux conceptions automobiles multi-flux, notamment celles utilisant des réseaux de neurones convolutifs (CNN) et des réseaux à transformateurs en périphérie, comme les passerelles et les hubs de vision à base d'IA dans la télématique vidéo pour les flottes de véhicules professionnles, les applications de vision panoramique à 360° et d'enregistrement vidéo, ainsi que les systèmes d'aide à la conduite (ADAS).
Toujours selon Ambarella, ces applications peuvent toutes tirer parti des caractéristiques du CV7 pour son traitement simultané de plusieurs flux vidéo jusqu'à 8Kp60 et la qualité d'image de haut niveau fournie tout en affichant une faible consommation d'énergie.
« Venant compléter notre gamme de SoC d'IA embarquée, avec plus de 39 millions d'unités livrées à ce jour, le CV7 permet aux développeurs de caméras de sécurité grand public et professionnelles d’intégrer des fonctionnalités d'imagerie les plus avancées et les meilleures performances d'IA embarquée, pour une analyse vidéo améliorée et une qualité d'image supérieure dans leurs produits de nouvelle génération », précise Fermi Wang, président et directeur général d'Ambarella.
De plus, la très faible consommation énergétique de ce nouveau SoC réduit les besoins en gestion thermique, permettant ainsi des formats plus compacts et une autonomie accrue pour des applications AIoT.
Comparé à son prédécesseur, le CV5, Ambarella indique que le circuit CV7 consomme 20 % d'énergie en moins, notamment grâce à la technologie de gravure en 4 nm de Samsung, une première pour Ambarella sur ce nœud technologique.
Le CV7 est également conçu, souligne Ambarella, selon la philosophie de conception dite "algorithme d'abord" permettant d'exécuter efficacement toutes les tâches de traitement simultanément, afin d’obtenir des. niveaux d’IA par watt optimum.
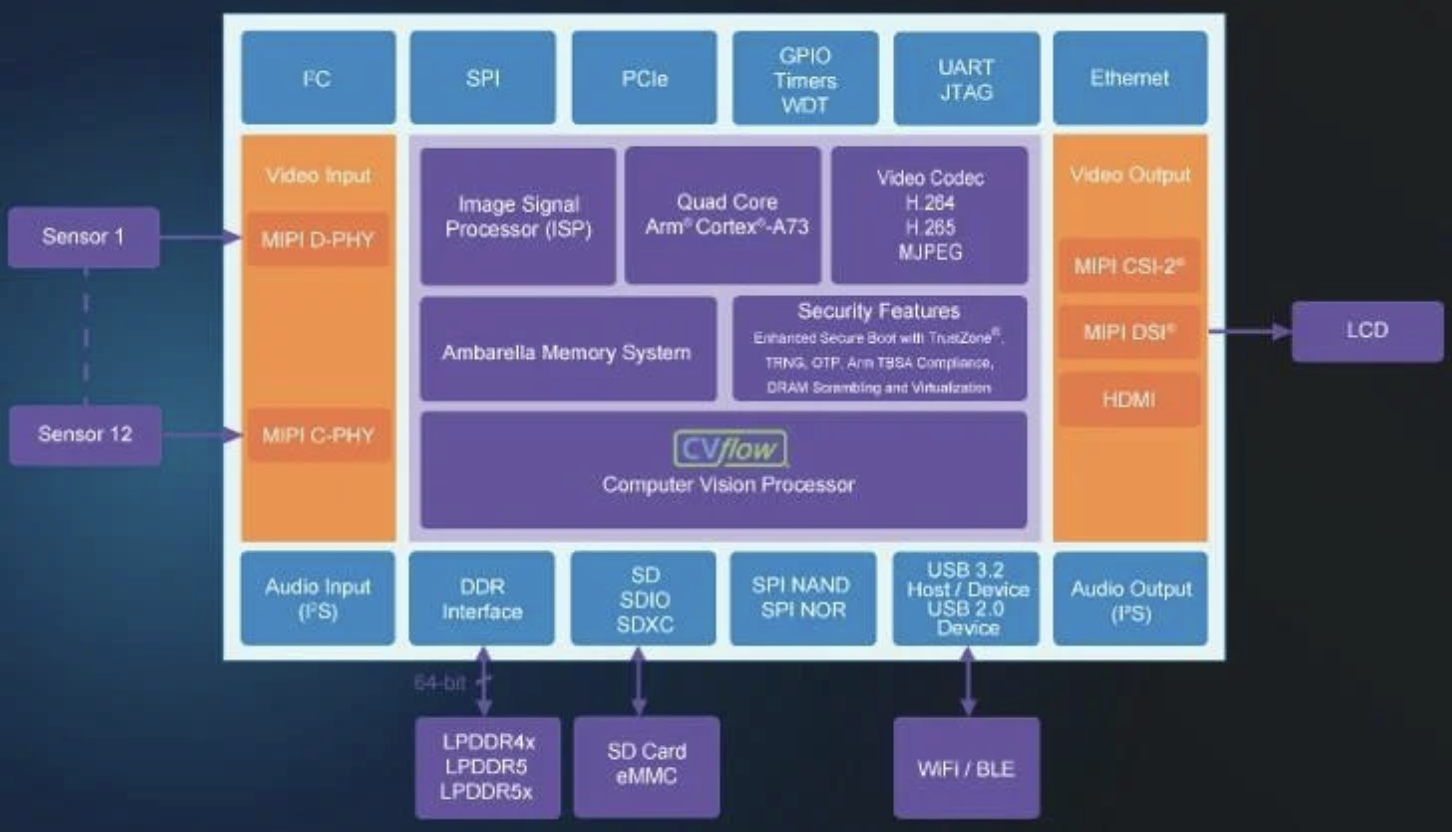
Le CV7 intègre l'accélérateur d'IA propriétaire d'Ambarella et un processeur de signal d'image (ISP) qui supporte une plage dynamique étendue (HDR), la correction de la distorsion pour les caméras fisheye et le filtrage temporel à compensation de mouvement 3D. Le circuit intégre en outre un bloc d'encodage vidéo (H.264, H.265, MJPEG), ainsi que quatre coeurs Arm Cortex-A73, flanqués d’une interface de mémoire Dram 64 bits, des entrées/sorties et d'autres fonctions, afin d'offrir aux utilisateurs une puce-système de vision IA puissante et efficace.
Les performances IA affichées par le circuit sont assurées par l'accélérateur d'IA propriétaire CVflow de troisième génération d'Ambarella, procurant des performances IA plus de 2,5 fois supérieures à celles du SoC CV5 de génération précédente.
Au-delà, le CV7 délivre une qualité d'image élevée même en situation de faible luminosité, jusqu'à 0,01 lux,
Le CV7 autorise enfin un encodage vidéo maximal d'un flux 4Kp240 unique, ou de deux flux 8Kp30, ce qui permettra aux prochaines générations de caméras de sécurité multi-images d'entreprise, de prendre en charge en simultané plusieurs flux, ainsi que les derniers réseaux d'IA fondés sur des transformateurs et les modèles de vision par le langage (VLM).





 300x300px.png)