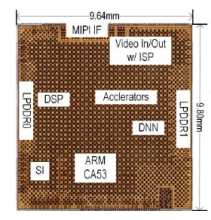
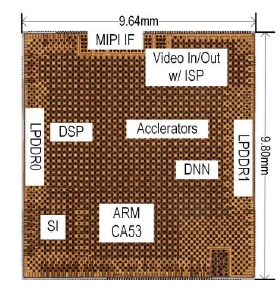
Toshiba a récemment donné quelques détails sur sa puce-système de reconnaissance d’image pour applications automobiles Visconti5 qui devrait être échantillonnée d’ici à la fin 2019 et qui embarque un bloc matériel d’accélération de réseaux de neurones profonds (DNN, Deep Neural Network). ...Grâce à cet accélérateur, le SoC de la firme japonaise devrait afficher une vitesse de traitement dix fois supérieure à celle du produit de précédente génération de Toshiba pour une éco-efficacité quatre fois meilleure.
 Selon la société nippone, les réseaux de neurones profonds sont capables d’effectuer des traitements de reconnaissance d’image bien plus précis que la reconnaissance de formes et l’apprentissage automatique conventionnels. Néanmoins l’exécution de tels algorithmes sur des processeurs classiques s’avère à la fois chronophage, car elle implique un nombre considérable d’opérations de multiplication-accumulation (MAC), et énergivore. Toshiba estime avoir surmonté ce défi avec un accélérateur DNN qui met en œuvre l’apprentissage profond dans le silicium.
Selon la société nippone, les réseaux de neurones profonds sont capables d’effectuer des traitements de reconnaissance d’image bien plus précis que la reconnaissance de formes et l’apprentissage automatique conventionnels. Néanmoins l’exécution de tels algorithmes sur des processeurs classiques s’avère à la fois chronophage, car elle implique un nombre considérable d’opérations de multiplication-accumulation (MAC), et énergivore. Toshiba estime avoir surmonté ce défi avec un accélérateur DNN qui met en œuvre l’apprentissage profond dans le silicium.
Ce bloc matériel se caractérise notamment par des unités MAC parallèles qui accélèrent le traitement des réseaux de neurones profonds. A ce titre, il intègre quatre processeurs dotés chacun de 256 unités MAC. En outre Toshiba a opté pour une architecture qui réduit les accès à la mémoire DRam. De fait, les puces-systèmes classiques ne disposent pas de mémoire locale pour stocker les données temporelles auprès du cœur d’exécution DNN et consomment beaucoup d’énergie lors des accès à la mémoire DRam, explique la société. Le Nippon a donc préféré implémenter de la SRam près de l’unité d’exécution DNN et diviser en sous-blocs de traitement le traitement DNN afin de conserver les données temporelles dans cette SRam. Par ailleurs, Toshiba a ajouté une unité de décompression à l’accélérateur. Les données de poids synaptique du réseau de neurones, compressées et stockées à l’avance dans la DRam, sont ainsi chargées via l’unité de décompression. Une astuce qui abaisse là encore la consommation énergétique.
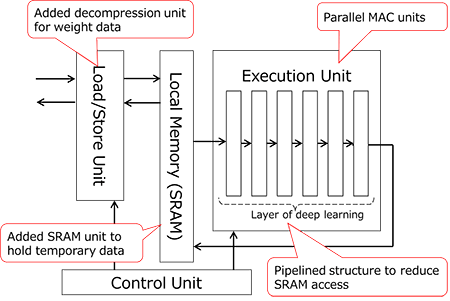 Enfin Toshiba a implémenté une architecture qui réduit aussi les accès à la SRam. L’apprentissage profond conventionnel nécessite en effet d’accéder à la mémoire SRam après le traitement de chaque couche DNN, ce qui consomme trop d’énergie. L’accélérateur se décline donc ici selon une structure en couches en pipeline dans l’unité d’exécution DNN, ce qui permet à une série d’opérations DNN d’être exécutées en un seul accès à la SRam.
Enfin Toshiba a implémenté une architecture qui réduit aussi les accès à la SRam. L’apprentissage profond conventionnel nécessite en effet d’accéder à la mémoire SRam après le traitement de chaque couche DNN, ce qui consomme trop d’énergie. L’accélérateur se décline donc ici selon une structure en couches en pipeline dans l’unité d’exécution DNN, ce qui permet à une série d’opérations DNN d’être exécutées en un seul accès à la SRam.
Selon Toshiba, le SoC Visconti5, qui embarque également un cœur Arm Cortex-A53 et qui sera échantillonné à partir de septembre (lire notre article ici), est conforme aux exigences de la norme de sûreté de fonctionnement pour applications automobiles ISO 26262.
Vous pouvez aussi suivre nos actualités sur la vitrine LinkedIN de L'Embarqué consacrée à l’intelligence artificielle dans l’embarqué : Embedded-IA https://www.linkedin.com/showcase/embedded-ia/




 300x300px.png)