
[TRIBUNE de Johan Kraft, PERCEPIO] L'un des aspects les plus sous-estimés d'une application temps réel multithread est qu'il ne suffit pas de simplement regarder le code pour comprendre pleinement le comportement et les performances de l'application. Il faut savoir comment les différentes parties communiquent entre elles et disposer de beaucoup d’autres informations. Combien de temps faut-il pour exécuter les tâches ? Y a-t-il des conditions de concurrence potentielles ou des blocages ? Les exigences de timing sont-elles respectées ? etc.
Il peut exister de nombreuses différences entre ce que doit faire l'application et ce qu'elle fait réellement, et ces différences sont à la fois difficiles à voir dans le code et difficiles à tester. Il s'agit ici d'un défi pour tous les développeurs qui travaillent avec du code multithread, qu'ils utilisent un système d’exploitation temps réel (RTOS) ou Linux, et celui-ci est mieux maîtrisé si l’on utilise des outils de diagnostic de trace visuelle qui donnent un aperçu de ce que j'appelle le “côté obscur” du code. Avec cette approche, il devient alors possible de “voir” littéralement comment il se comporte lors de son exécution. Une chronologie visuelle est donc un bon point de départ.
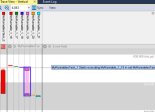
 Voir les événements logiciels, les messages et l'exécution des tâches étalés dans le temps est important dans de nombreuses situations, par exemple lorsque l'emplacement précis d'un bogue ne ressort pas de manière évidente des symptômes. Car bien qu’un ordinateur puisse être phénoménal dans les calculs et les recherches dans les journaux de texte, souvent l'on ne sait pas exactement quoi rechercher. Or, en matière de reconnaissance visuelle de formes, le cerveau humain excelle. Une chronologie visuelle montrant les événements logiciels donne alors un aperçu du fonctionnement interne de l'application intégrée et constitue un bon point de départ si l'on a besoin d'approfondir la recherche de bogues.
Voir les événements logiciels, les messages et l'exécution des tâches étalés dans le temps est important dans de nombreuses situations, par exemple lorsque l'emplacement précis d'un bogue ne ressort pas de manière évidente des symptômes. Car bien qu’un ordinateur puisse être phénoménal dans les calculs et les recherches dans les journaux de texte, souvent l'on ne sait pas exactement quoi rechercher. Or, en matière de reconnaissance visuelle de formes, le cerveau humain excelle. Une chronologie visuelle montrant les événements logiciels donne alors un aperçu du fonctionnement interne de l'application intégrée et constitue un bon point de départ si l'on a besoin d'approfondir la recherche de bogues.
Une meilleure compréhension lors du débogage signifie qu'il y aura moins de conjectures et de meilleures chances de trouver la ou les causes profondes. C'est également d'une grande aide dans les cas où une méthode traditionnelle comme l'arrêt du système sur des points d'arrêt ne peut pas être utilisée. Qu’en est-il alors du débogage utilisant l’instruction printf ? Oui, printf est facile à utiliser et parfois c'est vraiment tout ce dont on a besoin, mais son prix demeure élevé. Placer des impressions de débogage dans du code d’application urgent est risqué et ne s’adapte pas forcément très bien aux applications complexes et aux processeurs rapides. De plus, printf est généralement assez lent puisqu'il prend de l'ordre de plusieurs millisecondes par impression. Une solution optimisée pour le suivi des événements logiciels peut être 100 fois plus rapide, ce qui permet de collecter beaucoup plus d'informations sur la même période.
Veillez à mesurer le timing et les performances tout au long du projet de développement. Si c'est bien fait, on a la garantie de pouvoir détecter et résoudre tout problème pendant le développement plutôt que dans une course contre la montre juste avant la date de livraison promise. Le respect des spécifications de synchronisation est crucial pour les systèmes temps réel qui ont des exigences strictes, mais il est également important pour l'expérience utilisateur de presque tous les systèmes embarqués. Personne n'apprécie un écran tactile ou un routeur Wi-Fi lent qui ne fournit pas le débit promis. Encore une fois, la cause première peut ne pas être évidente à partir du code source, et le simple fait de passer à un processeur plus rapide pourrait ne rien apporter si le véritable problème est une mauvaise conception logicielle.
Si vous vous retrouvez dans “l’enfer du débogage” avec un projet incluant des quantités massives de données liées au débogage qui vous prennent toute votre énergie et empêchent le projet d’avancer, les diagnostics de trace visuelle peuvent vous aider. Car, le non-respect des meilleures pratiques en matière de conception logicielle pour les applications à base de RTOS est souvent un facteur majeur d’échec, et cela peut se manifester par exemple sous la forme de performances médiocres, d'une charge de processeur élevée ou d'erreurs passagères.
De nombreuses dépendances entre les tâches sont un autre signal courant indiquant que la conception pourrait être améliorée. Même les systèmes mal architecturés peuvent fonctionner aujourd'hui, mais ils auront un comportement complexe et chaotique, combiné à une faible testabilité, ce qui augmentera le risque de bogues insaisissables qui pourront s'infiltrer dans les appareils de production. Et ils seront presque certainement fragiles, de sorte que de petits changements dans le code ou dans l'environnement risqueront de provoquer leur échec.
 Ici les diagnostics de trace visuelle aident le développeur à analyser et à améliorer la conception de ses logiciels et à garantir un comportement stable et fiable du système. Si l'on peut détecter les défauts de conception des logiciels au plus tôt, moins de modifications seront nécessaires pour les corriger. Les améliorations de conception peuvent également conduire à de meilleures performances et à une réactivité accrue du système, ce qui à son tour pourrait vous permettre de sélectionner un processeur plus rentable pour réduire les coûts de la liste de matériels ou d'utiliser une fréquence d'horloge plus basse pour une autonomie plus longue de la batterie.
Ici les diagnostics de trace visuelle aident le développeur à analyser et à améliorer la conception de ses logiciels et à garantir un comportement stable et fiable du système. Si l'on peut détecter les défauts de conception des logiciels au plus tôt, moins de modifications seront nécessaires pour les corriger. Les améliorations de conception peuvent également conduire à de meilleures performances et à une réactivité accrue du système, ce qui à son tour pourrait vous permettre de sélectionner un processeur plus rentable pour réduire les coûts de la liste de matériels ou d'utiliser une fréquence d'horloge plus basse pour une autonomie plus longue de la batterie.
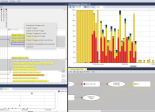
A ce niveau, utilisez un outil de traçage utile pour diffuser en continu les données de trace vers l'ordinateur hôte, où l’on peut stocker des enregistrements très longs si nécessaire et même afficher les données en direct sur l'écran. Le Trace Streaming permet par exemple de surveiller les tests du système ou de traquer des erreurs rares et difficiles à reproduire. Au-delà, les diagnostics de trace visuelle permettent de repérer les anomalies dans des aperçus visuels de haut niveau et d'analyser des événements spécifiques pour découvrir exactement ce qui s'est passé.
Enfin ces diagnostics peuvent être réalisés sous la forme d'une solution purement logicielle ne nécessitant aucun matériel supplémentaire, pas même une sonde de débogage. Une solution qui suppose un certain coût en matière d'utilisation de la mémoire et du processeur, mais pas dans des proportions exagérées.
A travers cette manière de faire, il est conseillé de laisser la technologie opérante dans le système tout au long de son développement, des tests et même du déploiement. Car cette approche permet de consigner toutes les informations pertinentes d’une application, y compris les données internes et les états qui ne sont pas exposés pendant l'exécution. Celles-ci peuvent alors être tracées en parallèle avec la chronologie d'exécution visuelle pour fournir un aperçu approfondi de l’application au moment de son exécution.



 300x250px.png)