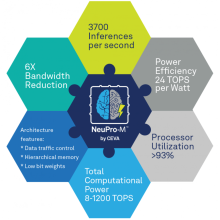
Sous le nom de NeuPro-M, Ceva a dévoilé sur le CES de Las Vegas son architecture de processeur de dernière génération, conçue pour l’exécution de logiciels d’intelligence artificielle et d’apprentissage automatique (AI/ML) et destinée aux développeurs de puces-systèmes SoC. Composée de multiples coprocesseurs spécialisés et accélérateurs configurables aptes à traiter simultanément divers réseaux de neurones profonds, l’architecture NeuPro-M, précise Ceva, affiche des performances de 5 à 15 fois supérieures à son prédécesseur, avec une puissance de calcul comprise entre 8 et 160 Tops (téraopérations par seconde) par cœur, extensible à plus de 1 200 Tops dans des configurations multicœurs. Une caractéristique qui lui permettrait de couvrir les besoins de nombreuses applications IA de périphérie de réseau (edge) sur des marchés comme l'automobile, la surveillance, la mobilité, l’électronique grand public, l'industriel, l’Internet des objets et la robotique.
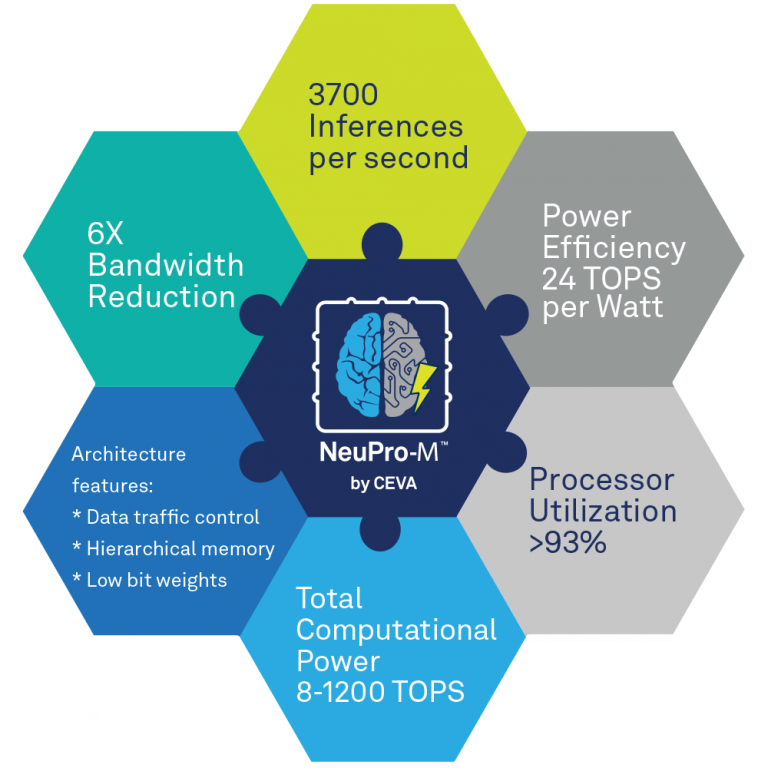 Pour l’heure, Ceva propose deux cœurs compatibles NeuPro-M préconfigurés : le NPM11 à moteur NeuPro-M unique (jusqu’à 20 Tops à 1,25 GHz) et le NPM18 à huit moteurs NeuPro-M (jusqu’à 160 Tops à 1,25 GHz). Selon la société, un seul cœur NPM11 affiche des performances cinq fois supérieures à son prédécesseur lors du traitement d’un réseau de neurones à convolution ResNet50 avec une bande passante mémoire réduite d’un facteur 6, ce qui se traduit par un niveau d’efficacité énergétique de 24 Tops/W.
Pour l’heure, Ceva propose deux cœurs compatibles NeuPro-M préconfigurés : le NPM11 à moteur NeuPro-M unique (jusqu’à 20 Tops à 1,25 GHz) et le NPM18 à huit moteurs NeuPro-M (jusqu’à 160 Tops à 1,25 GHz). Selon la société, un seul cœur NPM11 affiche des performances cinq fois supérieures à son prédécesseur lors du traitement d’un réseau de neurones à convolution ResNet50 avec une bande passante mémoire réduite d’un facteur 6, ce qui se traduit par un niveau d’efficacité énergétique de 24 Tops/W.
Si l’on en croit Ceva, NeuPro-M peut traiter toutes les architectures de réseaux de neurones connus ainsi que les réseaux de nouvelle génération comme les "transformeurs", les modèles auto-attentifs, les réseaux de neurones à convolution 3D et tous types de de réseaux de neurones récurrents. A cet égard, l’architecture NeuPro-M aurait été optimisée pour traiter plus de 250 réseaux de neurones, plus de 450 noyaux IA et plus de 50 algorithmes.
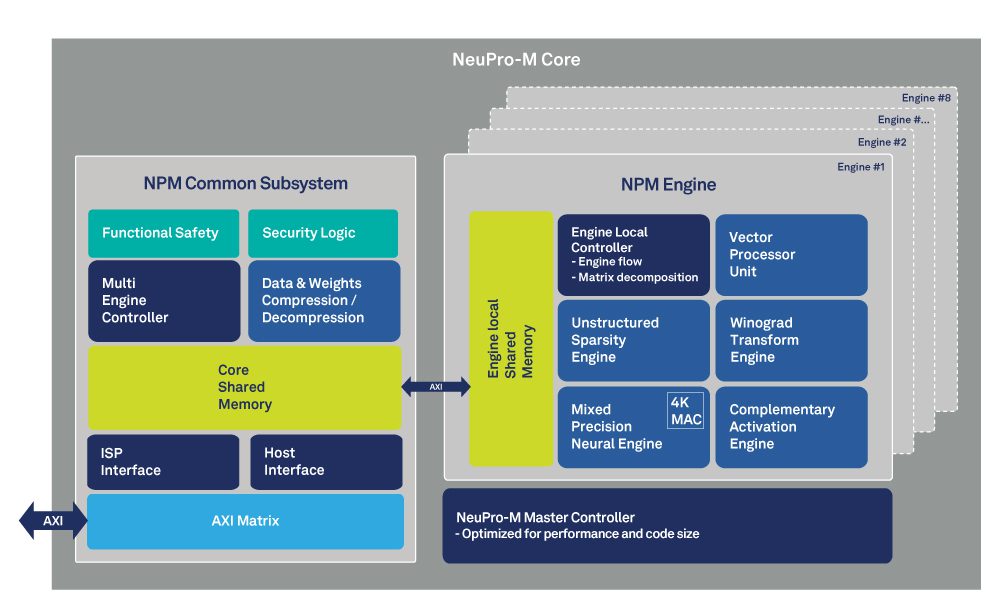
Les bonds en performances affichés par Ceva sont dus pour une bonne part à la structure hétérogène de l’architecture NeuPro-M qui se décline autour d’une matrice de 4K blocs multiplieurs-accumulateurs MAC à précision mixte (2-16 bits), d’un moteur de transformation Winograd pour les poids et les fonctions d’activation (qui divise notamment par deux le temps de convolution) et d’un moteur de codage parcimonieux (sparsity) qui évite les opérations sur des poids et des fonctions d’activation de valeur nulle au niveau de chaque couche, ce qui améliorerait les performances d’un facteur quatre tout en réduisant la bande passante mémoire et la consommation.
On y trouve aussi une unité de traitement vectoriel programmable (pour la prise en charge de nouvelles architectures de réseaux de neurones, quelle que soit la précision binaire des données) et des fonctions configurables de compression/décompression des données et des poids lors du stockage en mémoire (jusqu’à une précision sur 2 bits).
L’ensemble est associé à des mécanismes d’équilibrage de charge qui fluidifient la circulation des données entre tous ces éléments. En distribuant les fonctions de contrôle/commande à des contrôleurs locaux et en implémentant les mémoires locales de manière hiérarchique, l’architecture NeuPro-M atteint une flexibilité dans la répartition des flux de données qui, selon Ceva, se traduit, à tout moment, par plus de 90% d'utilisation des ressources et protège de la « famine » les différents coprocesseurs et accélérateurs.
Les premiers processeurs NeuPro-M, qui intègrent aussi des mécanismes de sécurité afin de protéger la propriété intellectuelle des utilisateurs, seront accessibles sous licence à tous au cours du deuxième trimestre 2022.



 300x250px.png)