Automobile, vidéosurveillance, drones, dispositifs portables sur soi sont aujourd’hui autant de marchés les yeux rivés sur les technologies d’intelligence artificielle et notamment les réseaux de neurones. Rien d’étonnant donc ...à voir les fabricants de semi-conducteurs (Renesas, Kalray, Qualcomm, Nvidia, etc.) avancer leurs pions dans ce domaine. Les fournisseurs d’IP ne sont pas en reste. Synopsys (avec la famille de processeurs de vision artificielle DesignWare EV6x) et Ceva (avec le DSP Ceva-XM6) ont ainsi récemment annoncé des plates-formes calibrées pour l’exécution de réseaux de neurones.
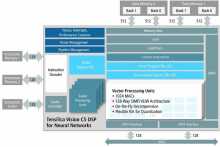
C’est aujourd’hui au tour de Cadence d’entrer dans la danse. A l’occasion de l’Embedded Vision Summit qui se tient du 1er au 3 mai à Santa Clara (Californie), la société américaine a dévoilé, sous le nom de Tensilica Vision C5, un cœur de DSP capable à lui seul, grâce à sa puissance de calcul de 1 TMAC/s pour une surface de silicium inférieure à 1 mm2, d’exécuter toutes les couches de calcul d’un réseau de neurones, tout en étant optimisé pour les applications de vision, de radar/lidar et de fusion de capteurs.
Selon Cadence, les systèmes de vision par caméra utilisés dans les véhicules automobiles, les drones et les systèmes de vidéosurveillance nécessitent deux types fondamentaux de traitement optimisés pour la vision. D’un côté, les données captées par la caméra doivent être enrichies par des algorithmes de calcul traditionnellement mis en œuvre dans les applications d’imagerie. De l’autre, les algorithmes à base de réseaux de neurones assurent la détection et la reconnaissance des objets. Or, selon l’Américain, les accélérateurs de réseaux de neurones actuellement disponibles sont généralement des accélérateurs matériels qui sont couplés à des DSP d’imagerie. Le logiciel des réseaux de neurones est alors scindé en deux parties, certaines couches réseau s’exécutant sur le DSP tandis que la gestion des couches de convolution est confiée à l’accélérateur, une combinaison qui (dixit Cadence) s’avère peu performante et peu éco-efficace.
A contrario, le DSP Vision C5 serait capable d’accélérer toutes les couches de calcul des réseaux de neurones à convolution (CNN) : couche de convolution (CONV), couche « entièrement connectée » (FC), couche de pooling (POOL) et couche de « normalisation ». Ce choix architectural, explique l’Américain, permet au DSP de vision/imagerie d’exécuter en toute indépendance des applications d’amélioration graphique, tandis que le DSP Vision C5 gère toutes les tâches d’inférence. En éliminant les mouvements de données inutiles entre les deux DSP, le processeur Vision C5 consommerait dans ces conditions moins d’énergie que les accélérateurs concurrents tout en offrant un modèle simple de programmation monoprocesseur pour réseaux de neurones.
Dans le détail, le DSP Vision C5 dispose d’une capacité de calcul de 1 TMAC/s, soit quatre fois plus que le DSP Vision P6, avec 1024 blocs MAC 8 bits ou 512 blocs MAC 16 bits. Il se déploie selon une architecture SIMD (Single Instruction on Multiple Data) VLIW (Very Long Instruction Word) avec mode SIMD 8 bits/128 canaux ou 16 bits/64 canaux. Doté d’interfaces iDMA et AXI4, il est également conçu pour les circuits multicœurs et utilise les même outils logiciels que ceux mis en œuvre par les DSP Vision P5 et P6.
Selon Cadence, le DSP Vision C5 est jusqu’à six fois plus rapide que les processeurs graphiques (GPU) du commerce au banc d’essai AlexNet CNN, et jusqu’à 9 fois plus rapide au banc d’essai Inception V3 CNN. Il est également fourni avec un outil de mappage qui transforme n’importe quel réseau de neurones entraîné avec des environnements comme Caffe ou TensorFlow en un code exécutable et optimisé pour le processeur Vision C5.






 300x250px.png)