Avec les plates-formes ACAP, Xilinx veut lancer une révolution dans le monde des FPGA« C’est un changement de paradigme technologique majeur pour l’industrie et, en termes d’ingénierie, notre réussite la plus significative depuis l’invention du FPGA ». C’est en ces termes plus qu’enthousiastes que Victor Peng, le président et CEO de Xilinx, décrit l’architecture ACAP (Adaptive Compute Acceleration Platform) ...qui doit propulser la société américaine au-delà du (petit) monde des FPGA et l’amener au-delà du cercle des développeurs purement matériels. Une stratégie que le spécialiste des composants programmables avait déjà entamée avec ses puces-systèmes SoC de la famille Zynq. Selon Xilinx, un circuit ACAP est une plate-forme de traitement intégrée, multicœur et hétérogène, qui peut être modifiée au niveau hardware pour s’adapter aux besoins de multiples applications et charges de travail. Une adaptabilité qui pourra être mise en oeuvre de manière dynamique en cours de fonctionnement et qui, dixit la société américaine, permettra d'atteindre des niveaux de performances brutes et de performances/watt avec lesquels les processeurs généralistes (CPU) et les processeurs graphiques sont incapables de rivaliser.
Dans l’absolu, développeurs matériels et logiciels pourront concevoir des produits architecturés autour d’une plate-forme ACAP pour des applications s’exécutant non seulement dans le nuage, mais aussi en périphérie de réseau (edge) et dans les équipements d’extrémité. Selon la description donnée par Xilinx, un circuit APAC a vocation à associer sur une seule puce une nouvelle génération de matrice FPGA avec mémoire distribuée et blocs DSP programmables au niveau matériel, un SoC multicœur (avec processeurs d'application et processeurs temps réel) et un ou plusieurs moteurs de calcul programmables au niveau logiciel mais adaptable au niveau matériel, le tout étant relié par un réseau-sur-puce (NOC, Network-On-Chip). Côté entrées/sorties, on pourra y trouver des contrôleurs mémoire programmables, des blocs d’interface SerDes et des convertisseurs A/N et N/A avec frontaux RF, voire de la mémoire HBM (High Bandwidth Memory) selon les variantes. Les développeurs logiciels se verront offrir la possibilité d'utiliser des outils C/C++, OpenCL et Python pour élaborer leurs systèmes architecturés autour de puces APAC, sachant que ces dernières seront aussi programmables au niveau RTL via des outils FPGA, précise Xilinx. « C’est clairement là que réside le futur des architectures de calcul, indique Patrick Moorhead, le fondateur de la société d’études Moor Insights & Strategy. On parle ici de la capacité à réaliser du séquençage génomique en quelques minutes au lieu de jours. On parle aussi de centres de données capables de programmer des serveurs afin qu’ils modifient leurs charges de travail en fonction des besoins à un instant T. Ils pourront réaliser du transcodage vidéo le jour puis de la reconnaissance d’image la nuit. » Connu sous le nom de code d’Everest, le premier membre de la famille ACAP sera gravé en technologie TSMC 7 nm et devrait présenter des performances vingt fois supérieures à celles du plus récent des FPGA Virtex VU9P 16 nm dans l’exécution de réseaux de neurones profonds. Les têtes radio déportées 5G bâties sur la puce Everest devraient, quant à elles, afficher une bande passante quatre fois supérieure à celles architecturées autour de FPGA 16 nm. Le tape-out du circuit Everest (avant son envoi en fonderie) devrait être prêt d’ici à la fin de l’année.
|
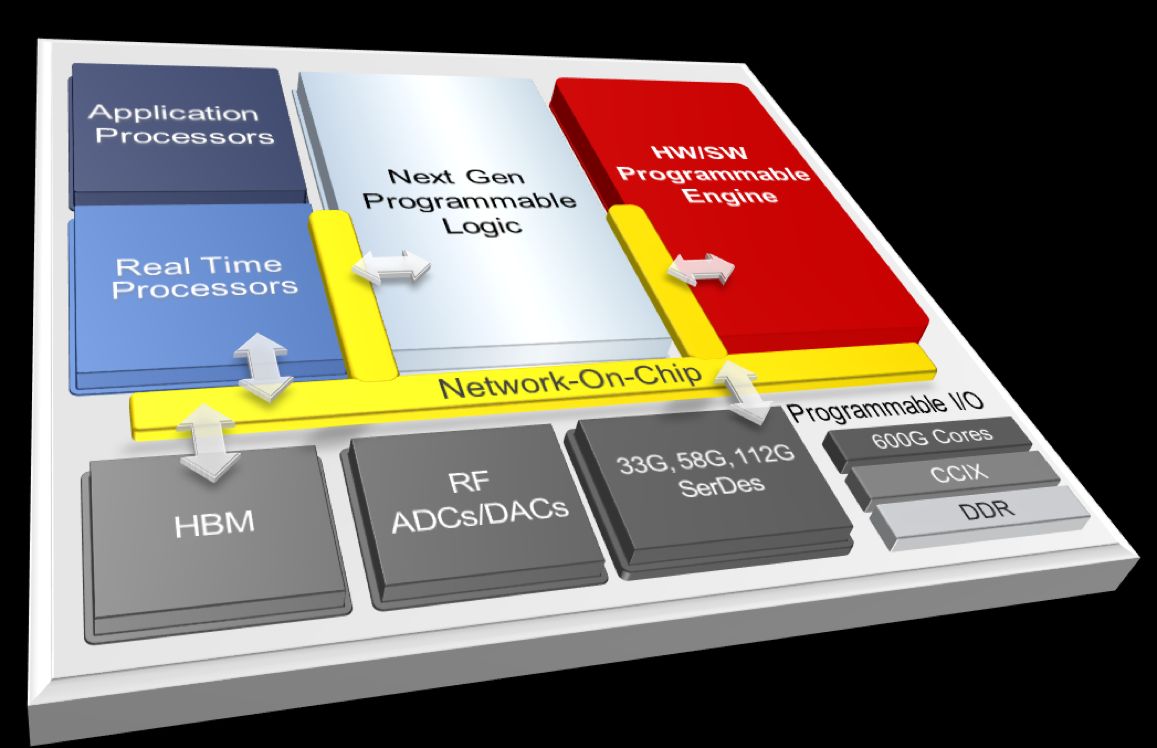 Pour Xilinx, l’architecture ACAP, qui a nécessité quatre ans de développement et plus d’un milliard de dollars d’investissement, est taillée pour accélérer de nombreuses applications dans le domaine émergent du Big Data et de l’intelligence artificielle (IA) : transcodage vidéo, gestion de base de données, compression de données, calcul d’inférences IA, génomique, vision artificielle, accélération réseau, etc.
Pour Xilinx, l’architecture ACAP, qui a nécessité quatre ans de développement et plus d’un milliard de dollars d’investissement, est taillée pour accélérer de nombreuses applications dans le domaine émergent du Big Data et de l’intelligence artificielle (IA) : transcodage vidéo, gestion de base de données, compression de données, calcul d’inférences IA, génomique, vision artificielle, accélération réseau, etc.