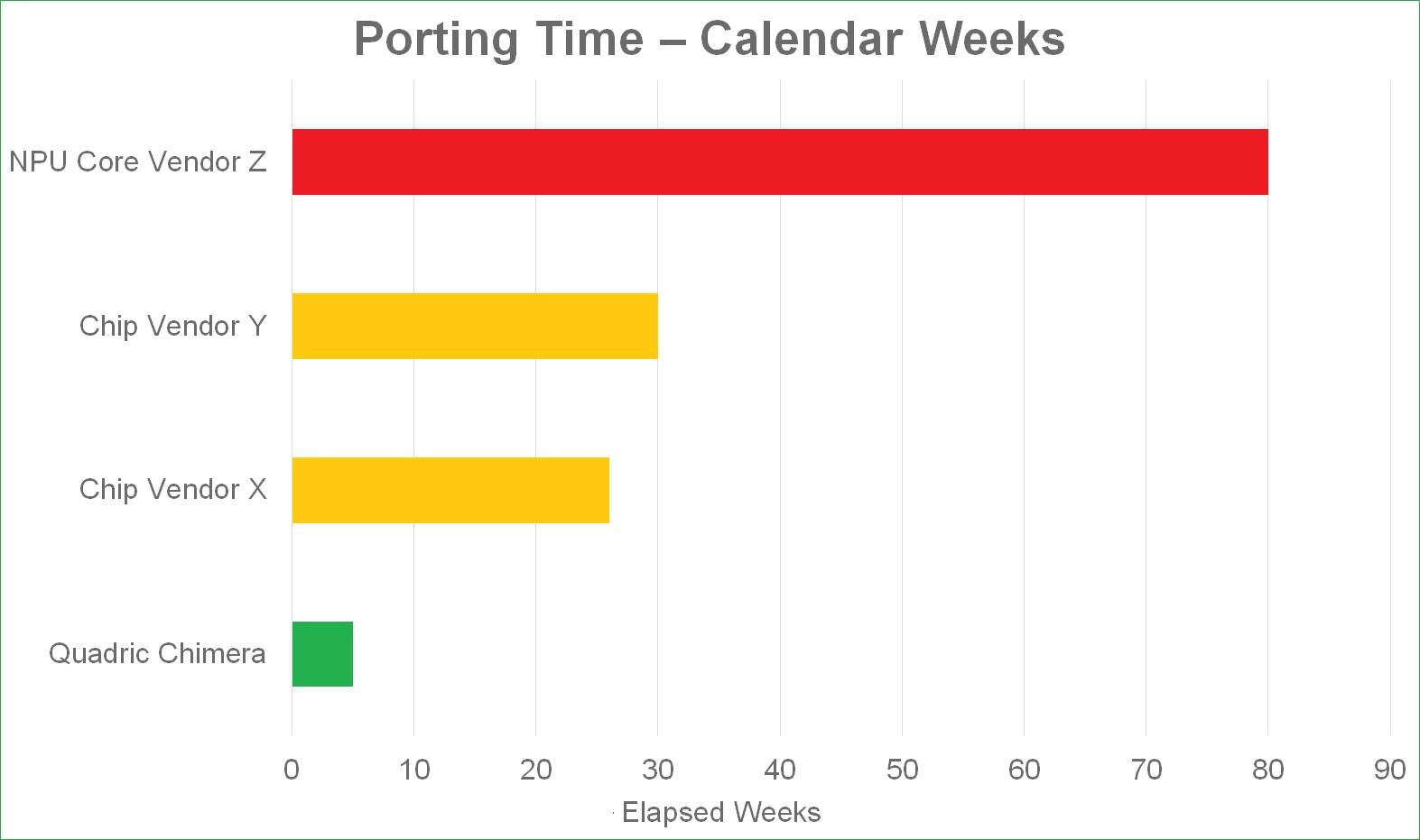
Le modèle de langage LLM Llama 2 arrive déjà sur les processeurs neuronaux embarqués de la société Quadric[EDITION ABONNES] Créée en 2016, la société californienne Quadric annonce la disponibilité immédiate du modèle de langage de grande taille LLM Llama 2 sur ses blocs d’IP GPNPU (General Purpose Neural Processing Unit) Chimera. L’Américain affirme que, contrairement à d'autres fournisseurs d’IP ou de processeurs d’application, il a pu ajouter cette prise en charge grâce à un simple portage logiciel sans modifications matérielles, de telle sorte que les conceptions existantes peuvent immédiatement exécuter le modèle Llama 2. Pour rappel, les modèles de langage, qui se cachent généralement derrière les agents conversationnels et l’intelligence artificielle générative, permettent à une machine de comprendre et de générer du texte en langage naturel. Dévoilé en juillet dernier et présenté comme concurrent de GPT-4 (OpenAI), Llama 2 est un modèle de langage de grande taille LLM au sens où il s’appuie sur de vastes corpus de textes de diverses sources. Open source, il est en outre gratuit pour un usage commercial. Quadric précise qu’il a suffi de quatre semaines (et l’équivalent de treize ingénieurs) pour porter une version quantifiée INT8 de Llama2 sur la plateforme Chimera et ajuster les performances. Deux nouvelles couches d'opérateurs ML (Machine Learning) et deux variantes de noyaux d'opérateurs existants ont été codées en C++ par l'équipe Applications de la société pour faire fonctionner le modèle. Un investissement supplémentaire de deux semaines a permis d'affiner les performances et la précision des "corner cases" pour garantir le fonctionnement sur les trois modèles de la famille de processeurs de la série Chimera QB (les variantes 1 Tops, 4 Tops et 16 Tops en l’occurrence). Selon Quadric, ce portage somme toute rapide a été facilité par la structure des processeurs neuronaux GPGNU Chimera. Ceux-ci s’appuient sur une architecture matérielle et logicielle optimisée pour le traitement de tâches d’intelligence artificielle en périphérie de réseau (edge). Mais, selon la jeune société, ils offrent la possibilité de traiter à la fois les graphes d'apprentissage automatique (ML) et les algorithmes C++ de traitement de données parallélisées sur une architecture unifiée. Et ce alors que la plupart des solutions concurrentes associent des grappes de processeurs généralistes (CPU) à des accélérateurs neuronaux (NPU) propres à une application donnée. Dans le détail, le GNGPU à 4 Tops Chimera QB4 affiche une éco-efficacité de 225 tokens/s/watt lors de l’exécution du modèle Llama 2 15M, et ce dans une technologie de gravure 5 nm pour une empreinte silicium de seulement 2,5 mm2. Selon Quadric, le portage de Llama 2 sur les futures puces Snapdragon de Qualcomm sera disponible dans les smartphones courant 2024. Idem pour les puces de MediaTek. Quant aux fournisseurs de blocs d’IP Cadence et Ceva, ils sont dans l’obligation de redesigner leurs cœurs d’IP pour que les grands modèles de langage LLM puissent s’y exécuter, affirme Quadric. Vous pouvez aussi suivre nos actualités sur la vitrine LinkedIN de L'Embarqué consacrée à l’intelligence artificielle dans l’embarqué : Embedded-IA
|